“It's Just Autocomplete!”Or, To Master Autocomplete, First Master Everything
Cats Cats Cats Cats Cats
Many of the most capable large language models are trained on the task of "next token prediction". Guess the next word I'm going to type: "Four score and ". That's next token prediction. If you think this looks a lot like autocomplete, you're right! It is autocomplete. But you might have heard people on the Internet screaming "it's just autocomplete!" into each others' digital faces. So, is it just autocomplete?
First, you can be better or worse at autocomplete. "Four score and cats cats cats cats cats." Always guessing "cats" is a form of autocompletion. Does it mean you're good at autocomplete? No, not really. "Four score and seven years ago" is probably better.1
But to guess that, you need to be familiar with Lincoln's Gettysburg Address. To guess better, you needed to know more. So knowing more can make you better at autocomplete. But can it go the other way around? Can getting better at autocomplete help you know more?2 I vote yes.
Beyond this point, you'll probably want to know what tokens are. If you do, plow on ahead. Otherwise, very simply, they're mostly pieces of words; if you want more detail there's a little section down below to help you out.
Now let's build up some intuition for why getting good at next token prediction might require you to learn some skills. We start with a little story.
The New Math3
Your fifth grader comes home from school and says, "They taught us some new math today but I didn't really get it. The teacher helped me with most of them, but I need help with the last one. Can you help me, please?" It's been quite a while since you've done any real math, but she's in fifth grade and you're pretty sure you can handle it.
"Yeah, of course, sweety! Let me see it." She pulls out this:
1 ⌗ 1 = 6
1 ⌗ 2 = 6
1 ⌗ 3 = 8
3 ⌗ 7 = 10
3 ⌗ 8 = __
"Umm, I don't know what that squarish symbol is, honey."
"Oh, it's lex. You know, like plus, minus, times, divided by, and lex."
"Uh huh…what does it do?"
"I don't remember. It's something like…I don't remember. But we have a test on it tomorrow. Mr. Amari says if we don't get at least 8 out of 10 of them right, we have to keep taking the test over and over again every day until we do. Even on the weekend!"
You stare at it for a while - it seems like there's a pattern, but you can't make any sense of it. You sigh and say, "OK. I can't really help you much with this, honey."
"Fine," she says. "I'll just memorize the four problems I have and if I see them on the test tomorrow, I'll fill in those answers. I'll just guess for everything else. I think I can memorize four problems."
"That sounds good. Do your best!"
The next day when she gets off the bus, she's slouching and staring at her shoes.
"You alright, honey?"
"I got a 2 out of 10. I thought you were going to help me!"
"Yeesh, sorry sweety. Let's head inside and try to figure this out."
The both of you plop down at the kitchen table, and she pulls out the corrected test:
5 ⌗ 1 = 6 ✘
7
11 ⌗ 2 = 6 ✘ 9
3 ⌗ 3 = 8 ✘
10
9 ⌗ 0 = 10 ✘ 8
1 ⌗ 1 = 6 ✔
12 ⌗ 4 = 6 ✘ 10
11 ⌗ 7 = 6 ✘ 11
0 ⌗ 13 = 8 ✘ 12
7 ⌗ 7 = 8 ✘
10
3 ⌗ 7 = 10 ✔
You stare again at the corrected test for a while, but still no luck. "I still don't think I can help you, hon. I'm sorry. Mr. Amari didn't do a review or anything?"
"I don't know. Whatever. But I have to take this stupid test again tomorrow. Ahhk. This is so stupid. I saw 8 new problems on the test; maybe I can memorize those too?"
"I'll help make flash cards."
She doesn't look any cheerier stepping off the bus the next day.
"I got a 4 out of 10. I hate stupid math. I couldn't remember all the problems I was supposed to memorize, and it didn't matter anyway because I still only would have gotten one more right."
"OK. We'll figure this out, sweety, no matter how long it takes."
The two of you sit down together again, this time a bit more resolute (you prepped some water and snacks.) You don't want to feel like you're letting your kid down, but you really can't tell what's supposed to be happening, so you just encourage her as talks through possible solutions for three hours until it finally dawns on her.
"'Lex' means you add up the number of letters in the English spelling of the two numbers! I figured it out! I don't remember learning that, but I get all the right answers on the previous tests!"
"Huh. Why are they teaching you that?"
"I dunno, but that definitely seems like it!"
"I'm sure it is. Good luck, you'll do great tomorrow!"
She's not beaming as she gets off the bus, but she's not sobbing either.
"How'd it go?"
"Well, I got 8 out of 10 right this time. I don't have to take the test anymore, but I was pretty sure I had it right, so I'm a little angry - it doesn't feel fair. But I'm relieved I get to rest now."
"Close enough, dear. You passed!"
It turns out the actual rule was "add up the number of letters in the English spelling of the two numbers including hyphens" which matters for numbers like "twenty-one" which hadn't shown up on the homework or tests yet.
How is This Helpful?
I'm sure some of the parallels between this scenario and actual LLM training already jump out, but let's draw them all out to make sure nothing gets missed.
First, your daughter is the model. "You" is just you - notice you never actually helped her. You just sat by and fed her while she tried to figure it out. (Woe is the machine learning researcher watching a training run.)
Look again at the first homework she brought home. Filling in that last blank is literally next token prediction. The skill she's trying to learn is the "lex" operator, but the way the teacher is figuring out whether or not she knows it is through autocomplete. In fact, basically every test you've ever taken was next token prediction,4 but none of them were testing you on next token prediction. Next token prediction is the evaluation strategy, not the skill.
But your daughter essentially wasn't taught the skill (or she was on her phone or whatever when the teacher was teaching it). Instead, she was just repeatedly shown examples and tested. This is how we train models - gather up a bunch of examples, tell the model to guess, and tell it which ones it gets right and which it gets wrong. To deal with this, at first, the daughter just memorized stuff she saw. Models do this too! (It's called overfitting.) This is why both the daughter and models are tested on examples they haven't seen before - if they actually know the skill, they'll be able to generalize what they've learned to unseen examples and still perform well. Memorization only gets one so far, both because tests are on unseen examples, but also because memory is finite. This is less the case with some models than with fifth graders (LLMs can memorize a lot of stuff), but it's still the case that memorization is not a great strategy to reliably perform well on next token prediction.
Instead, the daughter eventually figured out a rule for generating the correct next token. This rule both helps generalization performance and helps reduce the memory required for performing well. Much like the daughter, models are under both of these pressures when training,5 and, much like the daughter, they often figure out a rule. Some researchers call this "grokking", and you can actually see it in graphs of model performance over time as they train. They start off doing pretty poorly on some task, and they stay pretty bad at it for a while until at some point, BAM! They figure out a rule and the performance jumps up a ton. Here's a graph of performance over time from a paper that demonstrates this:
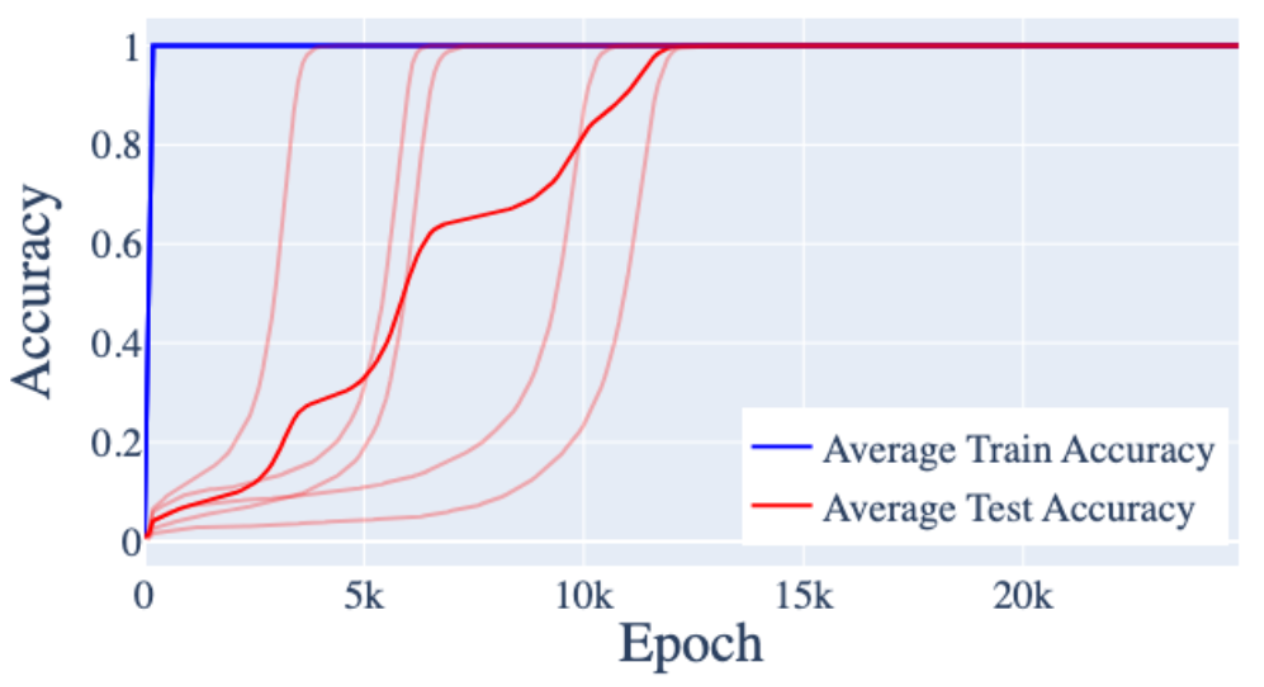
The blue line is how good the model is on examples it has seen before and the red lines are how good it is on examples it hasn't seen before. (They ran it five different times and also averaged them, which is why there are six red lines.) For a while, the model is pretty bad at examples it hasn't seen (it just memorized what it has seen) until it gets really good all of a sudden (because it figures out the skill).
Notice the daughter didn't actually end up doing perfectly on the test. This is because she learned a rule that was slightly different than the one the teacher was trying to teach her. In fact, it might not just be slightly different - it could be completely different, but just happen to have the same answers for these questions. This is possible because the teacher and the student were only "communicating" through the evaluation of examples. The teacher never actually stated the rule she was teaching to the student, and the student never actually stated the rule she learned back to the teacher. Instead, they just reached a point where the student's performance was good enough that they stopped.
This is why there's a bunch of research going on in model alignment and model interpretability. We don't yet know how to tell the models which rules we're trying to teach them (model alignment)6, and we don't yet know how to have the models tell us which rules they've learned (model interpretability).
This analogy isn't perfect, but hopefully it gives some intuition for why learning to do next token prediction can actually lead to the learning of skills that are not "just autocomplete".
OK Yeah But How?
At this point you may be saying, "Lovely extended analogy, but you haven't told me how models actually learn stuff in the real world." No, I haven't. But that's because these models are actually computer programs written in a programming language no one understands.
It's important to have a sense of what this language looks like to understand where the difficulty lies when trying to interpret the code of these powerful, alien computer programs. It's a little hard to describe without a lot of context, but if you want to read a very short attempt, read the section below. It's sufficient to say there are a small number of simple building blocks and when you combine billions of them and adjust all the dials correctly, the program will be able to speak a dozen languages and know math and swear words and programming and operas and all the world's capitals and poems and laws and racial slurs.
Even if we understand the building blocks of this language, we don't actually know how it knows this stuff, or even that it knows the same "lex" that we do because we are not fluent in this language. But folks are trying to become fluent!7 And they're making some progress! These folks poked at the numbers in a model that can tell you what objects are in pictures. They figured out that a tiny part of the model is built for curve detection, and they figured it out well enough that they could write it themselves from scratch using just this number language! These folks have written a programming language that forces you to write in a language similar to a Transformer8, and are working on translating between model language and other languages. These folks found out where and how a big language model memorized the fact that the Eiffel Tower is in Paris and then they tweaked the numbers to make it think it was in Rome instead. Some folks are taking a different approach and just asking these giant language models to explain smaller language models.
To give a glimpse at what "learning a skill" in this language might mean,
let's take a look at what
these folks
found when they trained a little model to do modular addition.9
Take a minute to think about the steps you'd take to do this… Whatever
you came up with is not what this model did. Essentially, it came up with
sine- and cosine-like functions, used those to represent the numbers and
perform addition on a circle using trigonometric identities, and then used
more trig identities to pull out the answer. Here's the key figure from the
paper for the full detail:
As a reminder, people had to spend days trying to decipher that the model did this. And then they had to perform a bunch of experiments to build evidence that their translation was correct because they were translating from a language no one knows. And even then, this is still just an approximation of what the model is doing.
And as another reminder, this wasn't a large language model, which means this model has never seen trigonometry. In fact, it has never seen anything but quiz questions; quiz questions that it was forced to answer over and over and over again. At first, it tried to memorize the answers, but after being tested a zillion times, it finally figured out things analogous to our sine and cosine functions, the trig identities that connect them, and the general skill of modular addition - all from being tested a lot.
Surprise, ___
In our little story and in the example above, we were only considering a single skill. But large language models are trained with next token prediction, and every test you've even taken was in the form of next token prediction, so every test you've ever taken can all be mixed together into one enormous, nightmare-test. Plus, you can make tests out of Wikipedia and books and everything else: "The first peoples of the Canberra area are the __."10 With this super-mega-ultra test, the models learn all sorts of skills at once. The problem is that we don't know which skills those are or how good the models are at them. All we can do is test them afterwards on specific tests and see how well they do.
And the models surprise us. Sometimes a model will fail a test on, say, metaphor understanding. A reasonable assumption is, "Well, metaphors are hard, so maybe this isn't a task that can be learned through next token prediction." Then someone trains a model that is bigger but still uses next token prediction11 and all of a sudden that model is good at metaphor understanding. Models acquiring new skills just by getting bigger is called emergence, and there are lots of examples. And then there are the skills we haven't even thought to test for - things the models could be good at that we haven't even asked for - the so-called "capabilities overhang." Lots of surprises in store.
So, is it autocomplete? Certainly. Is it just autocomplete? That's up to you. Does it just take autocomplete to pass the bar exam at the level of an average lawyer?12 Or get a 77% on the Advanced Sommelier theory test?13 Or score better than 90% of humans on the SAT? Or get the highest possible score on 9 out of 15 Advanced Placement (AP) exams?14 I've taken some of these tests, and I don't think of myself as performing just autocomplete. Maybe that's the problem? Or maybe valuing ourselves based on test performance is the problem? I dunno, man. This is all just _____.
Appendix
Tokens
So, let's talk "next token prediction". The "next" and "prediction" parts are familiar, but what's "token" doing in there? It means a couple things. Let's work through this with an example, and let's use this sentence as that example. How many words are in that sentence? There are two answers to that question: 15 and 12. 15 is probably the more intuitive answer - start at "Let's" and just add one to your count after each space. That's the answer the Word Count tool gives. But 12 is also correct: "let's", "this" and "example" are each in there twice, so there are really only 12 different words. This ambiguity is annoying when you talk about language a lot (like NLP researchers tend to do), so let's say that when you're moving your finger along the line and saying bigger numbers to yourself you are counting "tokens" not words.
It feels a little silly to use a new term for that sense and not the "unique words" sense since that first sense is the intuitive one, but this is where "token" shows its second use. It doesn't have to mean "a whole word". "Token" can just mean "part of a word". Depending on how you choose to tokenize, the word "bandolier"15 can have the tokens [band o lier] or [ba nd ol ier] or even [b a n d o l i e r]. So a token can be a letter, a few letters, the whole word, or even multiple words together.
Why is this useful? When setting up most large language models, the designer needs to define a "vocabulary". That is, they need to predefine the set of all the tokens that the model will be able to read and write. This set is usually tens of thousands of items long, but if you choose to tokenize by word and you don't include the word "neuroplasticity" in your vocabulary, the sentence "I research neuroplasticity" becomes "I research <unknown>" when your model reads it, which is going to make your model less useful.
So you typically tokenize to something less than full words, but where the tokens might still capture some meaning, maybe [ne uro pl astic ity].16 Having a vocabulary of these little word bits means the models can read and write words they've never seen before, which is useful.
It's also useful that tokens don't have to be parts of words, per se. Numbers can be tokens. Punctuation can be tokens. Computer code can be tokens. Mouse movements and clicks can be tokens.
Neural Network Language
What language are neural network written in? As a not-too-crazy simplification, start with the old formula for a line: mx + b. There are three numbers here: m, x, and b; and two operations: multiply and add. As a speaker of this language, you get to pick the m and b (the parameters), but the x is given to you by something out in the world (like your data). You do the multiplication and the addition and get a new number out, and for reasons that will seem arbitrary, to follow the rules of this language, if this new number ends up negative, you just throw it away and say it was zero. To build up a more complex sentence, you can take the result of your formula and throw it into another line formula. Let's change the letters to nw + c. Again, you get to pick n and c, but now w is actually the output of your previous formula, so the whole thing is n(mx + b) + c. And again, if the output is negative, throw it away and call it zero. Now you can do this billions more times, fitting all these little formulas into each other in increasingly complex ways. That giant nest of numbers is the language folks are trying to learn.
Notes
-
In some ways! Nudging everybody's text in the same direction might have negative consequences we haven't yet grappled with. ↩
-
Your answer to this question might hinge on your definition of "know". Other terms in this space that aren't well defined and lead to people using CAPS LOCK are "understand," "learn," "perceive" and "conscious". ↩
-
https://www.youtube.com/watch?v=-tg3C4bhhz4 or https://www.youtube.com/watch?v=UIKGV2cTgqA. (I left out the Bo Burnham one because it's cringey and kinda nsfw.) ↩
-
Except part of your driver's test, and they're working on that one. ↩
-
Assuming the model doesn't have way more parameters than it needs. If the model is overparameterized, it has more memory than it needs - it doesn't feel memory pressure and just tries to memorize everything. ↩
-
I mean, we know some ways of doing that, but none that perform as well as not telling them and just training a gigantic model. ↩
-
Though the number of people doing this is surprisingly small. ↩
-
Modular addition is like clock addition, so if our modulus is 12 like on a clock, 11 + 4 = 3 instead of 15. ↩
-
"Bigger" means it has more parameters (so it's a more complicated model), but it can be trained in basically the same way and on the same dataset. All that changes is compute time. ↩
-
https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4441311 ↩
-
92% on the Intro Sommelier test. ↩
-
Results from https://cdn.openai.com/papers/gpt-4.pdf ↩
-
A pretty word for an ugly thing ↩
-
This is actually how Llama-7B tokenizes it. ↩